
[머신러닝] Dropout (드롭아웃)
Updated:
Dropout이란 뭔지 알아보자.
Dropout
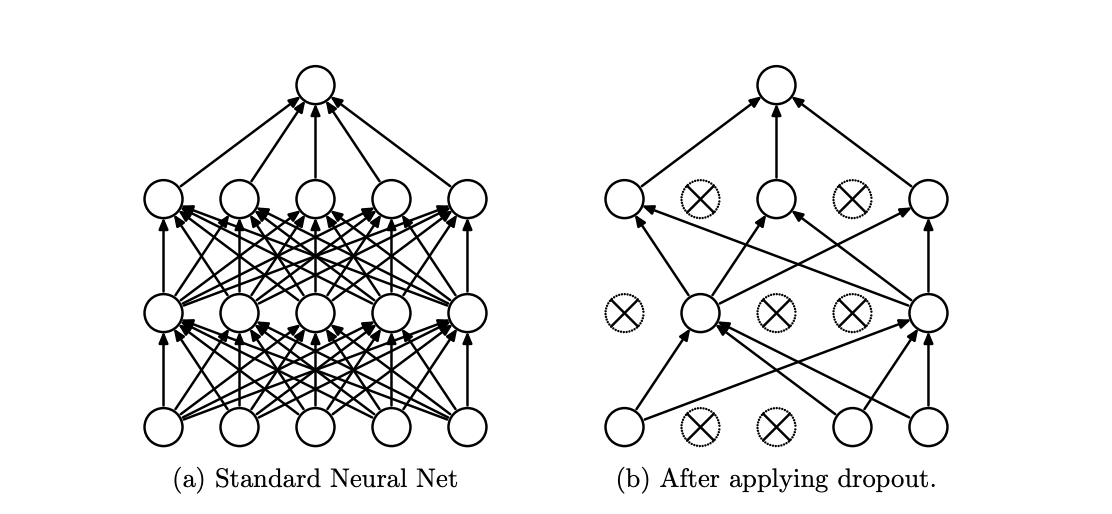 [1]
[1]
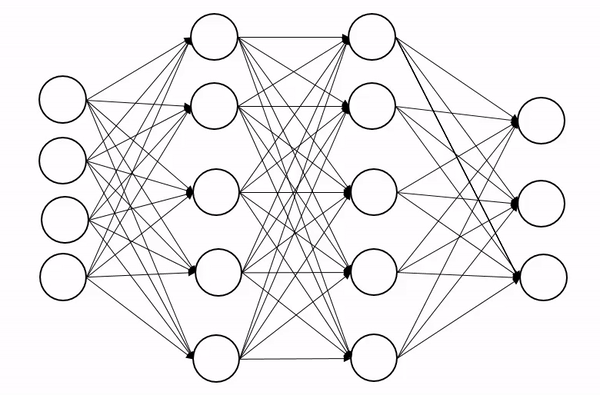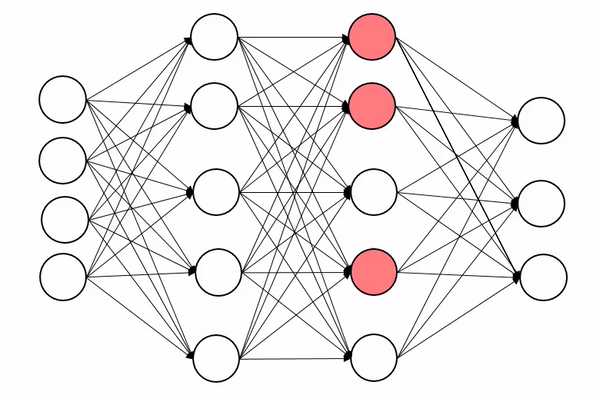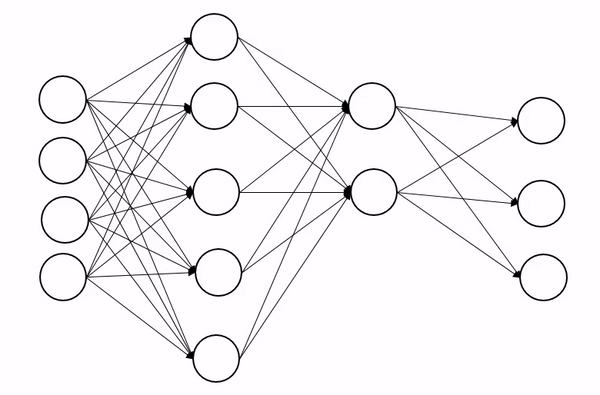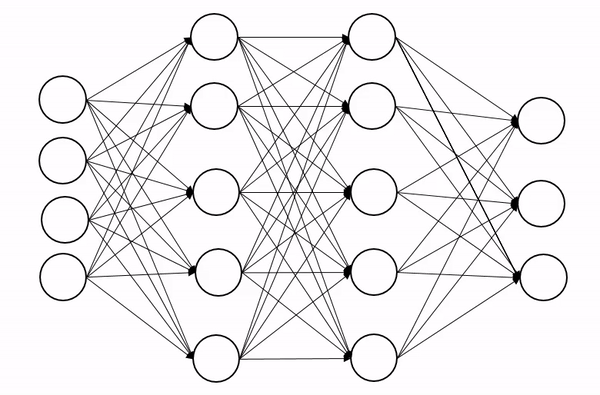 [2]
[2]
PyTorch 공식 문서[3]에서는 이렇게 말하고 있다.
During training, randomly zeroes some of the elements of the input tensor with probability
pusing samples from a Bernoulli distribution. Each channel will be zeroed out independently on every forward call.
This has proven to be an effective technique for regularization and preventing the co-adaptation of neurons as described in the paper Improving neural networks by preventing co-adaptation of feature detectors .
Furthermore, the outputs are scaled by a factor of $\frac{1}{1-p}$ during training. This means that during evaluation the module simply computes an identity function.
모델을 학습시킬 때 연결된 unit의 일부를 0으로 만들어서 regularization (성능 일반화)에 도움을 준다. 즉 overfitting을 막을 수 있다.
드롭아웃은 매번 다른 형태의 노드로 학습하기 때문에 여러 모델을 ensemble (앙상블) 하는 효과를 낼 수 있다. 앙상블은 같은 데이터로 여러 개의 서로 다른 모델을 훈련한 뒤 그 결과를 다수결 등으로 종합해서 통계적으로 덜 튀는 결과를 냄으로써 더 높은 정답률을 얻게 하는 방식이다 [4].
PyTorch Dropout 사용법
torch.nn.Dropout(p=0.5, inplace=False) # [3]
파이토치 드롭아웃의 p rate은 0으로 만들 비율, 즉 얼만큼 비활성화할 건지를 의미한다. (다시 말해, keep probability가 아니라 drop probability임!)
# Example [3]
m = nn.Dropout(p=0.2)
input = torch.randn(20, 16)
output = m(input)
모델에 드롭아웃을 추가할 때는 이런 식으로 할 수 있다.
# Example [2]
class Net(nn.Module):
def __init__(self, input_shape=(3,32,32)):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.conv2 = nn.Conv2d(32, 64, 3)
self.conv3 = nn.Conv2d(64, 128, 3)
self.pool = nn.MaxPool2d(2,2)
n_size = self._get_conv_output(input_shape)
self.fc1 = nn.Linear(n_size, 512)
self.fc2 = nn.Linear(512, 10)
# Define proportion or neurons to dropout
self.dropout = nn.Dropout(0.25)
def forward(self, x):
x = self._forward_features(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
x = F.relu(self.fc1(x))
# Apply dropout
x = self.dropout(x)
x = self.fc2(x)
return x
hidden unit에 적용하는 것이다.
참고 문서 [2]에서도 얘기하고 있는데 드롭아웃을 쓰면 training accuracy가 떨어지기 때문에 학습 epoch 수를 늘려야 한다.
파이토치 모델을 학습할 때 드롭아웃을 활용하고 싶으면 모델을 구현할 때 __init__ 메서드에서 드롭아웃을 정의하고 학습 및 검증 과정에서 model.train()이랑 model.eval()을 선언해 줘야 한다. 이를 명시함으로써 training 중에는 드롭아웃을 사용하고 evaluation (validation 및 test) 중에는 드롭아웃을 사용하지 않게 된다.
왜 training 중에만 드롭아웃을 사용할까?
드롭아웃 자체가 overfitting을 줄이고 모델 성능을 일반화하기 위한 랜덤 프로세스 기법이다. training 과정에서 일부러 노드를 제거해서 이전 회차에서의 weight를 참조하지 않고 모델이 오답을 내게 만들어서 최적화된 모델을 얻는 것이다. 그런데 validation이나 test 데이터셋에 대해서 드롭아웃을 쓰게 되면 어떤 노드를 제거했을 때가 제일 최적화된 상태인지 알 수 없기 때문에 모델 성능 평가를 제대로 할 수 없다 [5].
참고 문서 출처
[1] Srivastava, Nitish, et al. “Dropout: a simple way to prevent neural networks from overfitting.” The journal of machine learning research 15.1 (2014): 1929-1958.
[2] WandB - Implementing Dropout in PyTorch: With Example
[3] PyTorch Documentation
[4] Deepest Documentation
[5] Why disable dropout during validation and testing?
Leave a comment